
The concept of data science is not a recent development; it has existed
for decades. However, to engage in discussions about a field, it is
essential to give it a name. One of the pioneers in assigning a name to
this discipline was Peter Naur, who introduced the term "datalogy" in
the 1960s, defining it as "the science of the nature and use of data."
Over time, this term evolved into "science of data" and eventually
became known as "data science." Notably, in 1997, Jeff Wu delivered an
inaugural lecture provocatively titled "Statistics = Data Science?"—a
signal of the significant shift in data analysis approaches.
Furthermore, one of the earliest institutions to specialize in dedicated
research in this domain was the Research Center for Dataology and Data
Science at the Fudan University, Shanghai (China), established in 2007.
Data
science combines the skill set and expert knowledge of many different fields,
including machine learning, artificial intelligence, statistics and network science. This makes the field inherently interdisciplinary because each of these fields has its own history.
More detailed background information about this can be found in the following publications:
In general, the availability of data provides
opportunities in all fields of
science to gain new
information and to tackle
difficult problems. However, data alone do not provide information; first, they need to be
analyzed. This is what we call learning from data which is at the heart of data science. There is a large number of quite different data
types and in the following, I just want to mention three data types in more detail that
are also studied in my Lab. Specifically, I will describe:
1. Gene
expression data
2. Text
data
3. Network
data
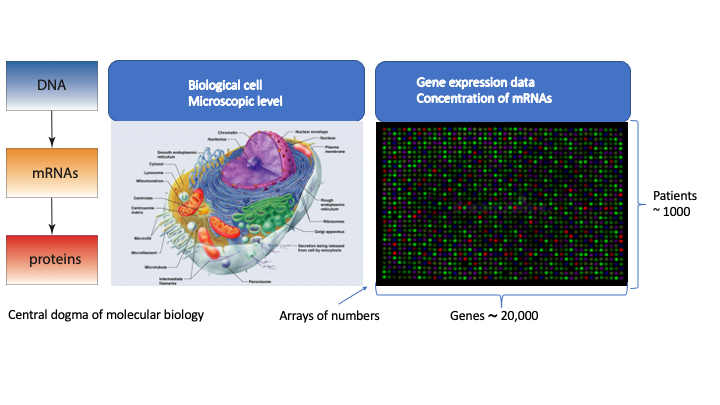
The first data type is called
gene expression data. Such data provide information from biological cells of
animals or plants about the activity of genes by measuring the concentration of
mRNAs. Humans have over ~20,000 genes which means that the resulting profiles obtained
from such genomics experiments correspond to high-dimensional arrays of numbers.
Using gene expression data does not only allow to learn about molecular
biological laws but also to gain a better understand of diseases and to help
developing treatments. The latter forms the basis of what is called
personalized medicine or precision medicine.
The following image visualizes the connection between molecular biology and the resulting measurements where rows correspond to patients and columns to the measurments of gene activity.
More details about gene expression data can be found in the following publication:
The second data type I would like to mention is text data. Text data differ significantly from gene expression
data because they are not presented as numerical values, but as symbol
sequences composed of letters from an alphabet. That means before any analysis of text data can be
conducted, a transformation, or mapping, of the symbol sequences to numbers needs
to be performed. However, already this mapping is very challenging and no
optimal solution currently exists. Still, examples like chatGPT demonstrate impressively capabilities of modern
deep learning methods.
More details about text data and their analysis can be found in the following publications:

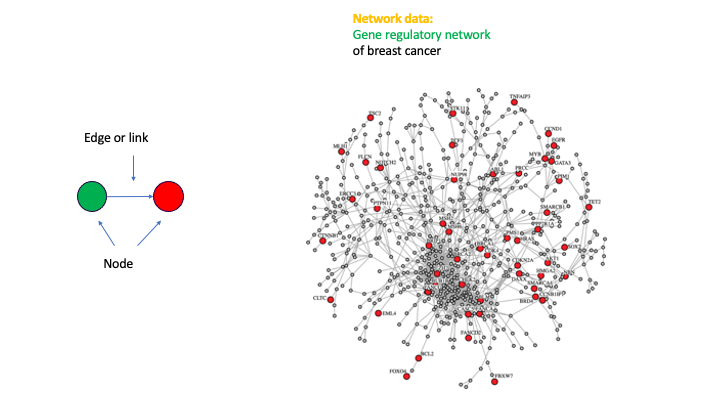
The third data type is called network
data. In general, networks, also called graphs, provide an elegant way to
represent the connectivity among discrete units. Such discrete units are called
nodes and the connections between these are called edges or links (see the image below). While the
most simple network consists of only two nodes and one edge, the combination of
many nodes and many edges can result in very complex networks. An example for
such a network is the gene regulatory network of breast cancer showing in the image below. This
network, inferred from data, is like a blueprint of the disease that shows a
global dependency structure among the genes. In general, the interrogation of
such networks allows to gain insights into the causal mechanisms that are present in disorders.
More details about gene regulatory networks, their inference and the analysis of networks can be found in the following publications:
From these examples you see that data science needs
to be very versatile by providing different analysis methods for the efficient
analysis of many different data types.
Despite the diversity of data and methods for
their analysis, there is a common underlying thread describing the
purpose of data science and that is “data science allows to make predictions”.
While this sounds simple, the challenge is to make systematic predictions by
minimizing prediction errors. Here statistical thinking is playing a key
role to complement approaches from artificial intelligence and machine
learning.
A more detailed description of our work can be found on the research page.
created with
HTML Creator .